What is Tokenization and How does it work?


Tokenization is a fundamental process in Natural Language Processing (NLP) and plays a crucial role in preparing text data for machine learning models. This blog post will break down what tokenization is, why it's important, and how it works with a concrete example.
What is Tokenization?
Tokenization is the process of splitting text into smaller, manageable pieces called tokens. These tokens can be words, subwords, characters, or other units depending on the tokenization strategy. The purpose of tokenization is to transform text into a format that can be effectively processed by machine learning algorithms.
Why is Tokenization Important?
Before any NLP model can analyze and understand text, it needs to be converted into a numerical format. Tokenization is the first step in this conversion process. By breaking down text into tokens, we enable models to handle, learn from, and make predictions based on textual data.
How Tokenization Works
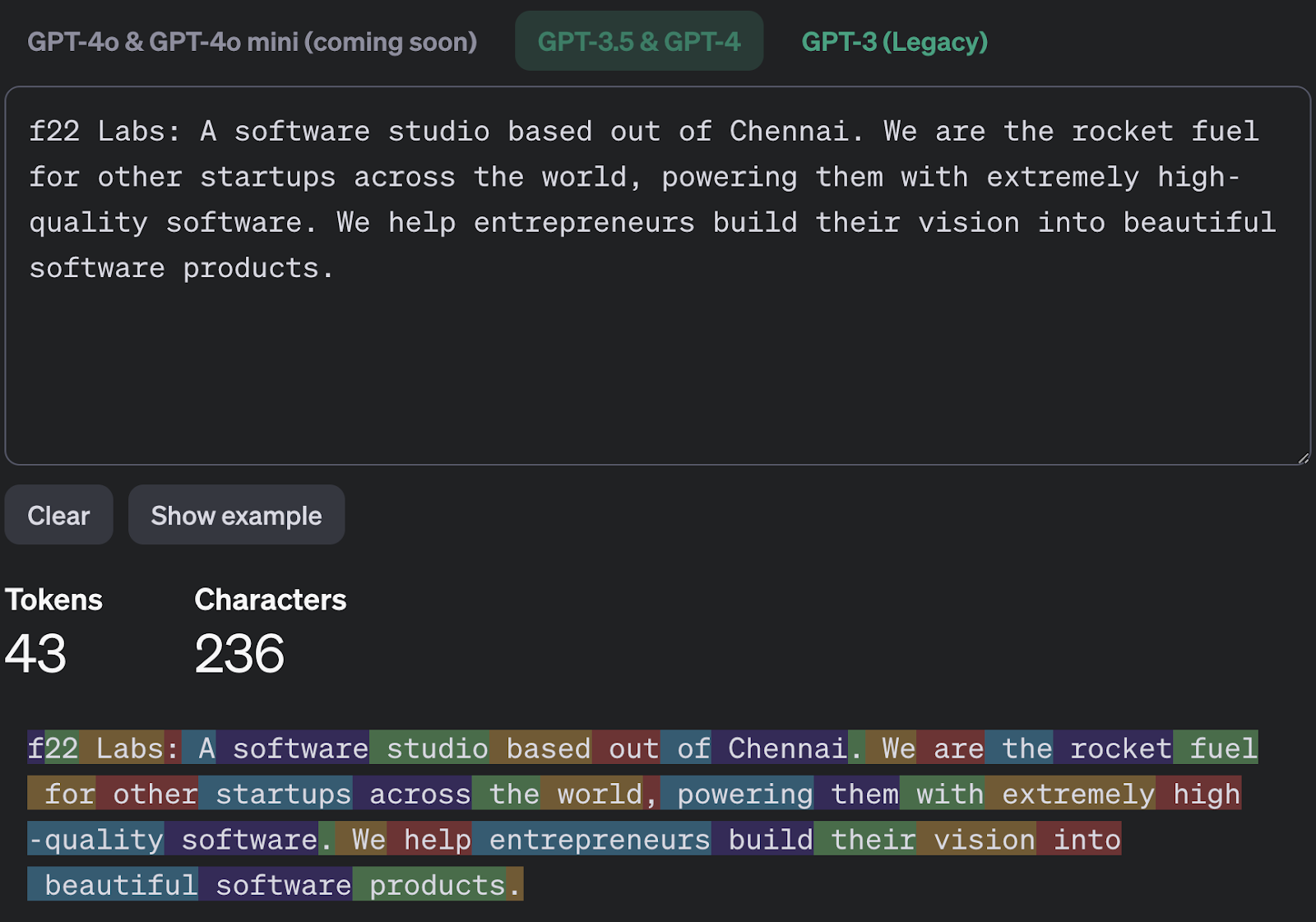
Let’s dive into a practical example to understand tokenization better. Consider the sentence:
"f22 Labs: A software studio based out of Chennai. We are the rocket fuel for other startups across the world, powering them with extremely high-quality software. We help entrepreneurs build their vision into beautiful software products."
Here’s a step-by-step breakdown of how tokenization works:
Step 1: Splitting the Sentence into Tokens
The first step in tokenization is breaking the sentence into smaller units. Depending on the tokenizer used, these tokens can be:
Words: ["f22", "Labs", ":", "A", "software", "studio", "based", "out", "of", "Chennai", ".", "We", "are", "the", "rocket", "fuel", "for", "other", "startups", "across", "the", "world", ",", "powering", "them", "with", "extremely", "high-quality", "software", ".", "We", "help", "entrepreneurs", "build", "their", "vision", "into", "beautiful", "software", "products", "."]
Subwords: the tokens might be more granular. For example, ["f22", "Lab", "s", ":", "A", "software", "studio", "based", "out", "of", "Chennai", ".", "We", "are", "the", "rock", "et", "fuel", "for", "other", "start", "ups", "across", "the", "world", ",", "power", "ing", "them", "with", "extremely", "high", "-", "quality", "software", ".", "We", "help", "entrepreneur", "s", "build", "their", "vision", "into", "beautiful", "software", "products", "."]
Characters: For character-level tokenization, the sentence would be split into individual characters: ["f", "2", "2", " ", "L", "a", "b", "s", ":", " ", "A", " ", "s", "o", "f", "t", "w", "a", "r", "e", " ", "s", "t", "u", "d", "i", "o", " ", "b", "a", "s", "e", "d", " ", "o", "u", "t", " ", "o", "f", " ", "C", "h", "e", "n", "n", "a", "i", ".", " ", "W", "e", " ", "a", "r", "e", " ", "t", "h", "e", " ", "r", "o", "c", "k", "e", "t", " ", "f", "u", "e", "l", " ", "f", "o", "r", " ", "o", "t", "h", "e", "r", " ", "s", "t", "a", "r", "t", "u", "p", "s", " ", "a", "c", "r", "o", "s", "s", " ", "t", "h", "e", " ", "w", "o", "r", "l", "d", ",", " ", "p", "o", "w", "e", "r", "i", "n", "g", " ", "t", "h", "e", "m", " ", "w", "i", "t", "h", " ", "e", "x", "t", "r", "e", "m", "e", "l", "y", " ", "h", "i", "g", "h", "-", "q", "u", "a", "l", "i", "t", "y", " ", "s", "o", "f", "t", "w", "a", "r", "e", ".", " ", "W", "e", " ", "h", "e", "l", "p", " ", "e", "n", "t", "r", "e", "p", "r", "e", "n", "e", "u", "r", "s", " ", "b", "u", "i", "l", "d", " ", "t", "h", "e", "i", "r", " ", "v", "i", "s", "i", "o", "n", " ", "i", "n", "t", "o", " ", "b", "e", "a", "u", "t", "i", "f", "u", "l", " ", "s", "o", "f", "t", "w", "a", "r", "e", " ", "p", "r", "o", "d", "u", "c", "t", "s", "."]
Step 2: Mapping Tokens to Numerical IDs
Once the sentence is tokenized, each token is mapped to a unique numerical ID using a vocabulary. The vocabulary is a predefined mapping that associates each token with a specific ID. For example:
Vocabulary:
{"f22": 1501, "Labs": 1022, ":": 3, "A": 4, "software": 2301, "studio": 2302, "based": 2303, "out": 2304, "of": 2305, "Chennai": 2306, ".": 5, "We": 6, "are": 7, "the": 8, "rocket": 2307, "fuel": 2308, "for": 2309, "other": 2310, "startups": 2311, "across": 2312, "world": 2313, ",": 9, "powering": 2314, "them": 2315, "with": 2316, "extremely": 2317, "high-quality": 2318, "products": 2319, "entrepreneurs": 2320, "build": 2321, "their": 2322, "vision": 2323, "into": 2324, "beautiful": 2325}Token IDs:
[1501, 1022, 3, 4, 2301, 2302, 2303, 2304, 2305, 2306, 5, 6, 7, 8, 2307, 2308, 2309, 2310, 2311, 2312, 2313, 9, 2314, 2315, 2316, 2317, 2318, 2301, 5, 6, 2320, 2321, 2322, 2323, 2324, 2325]So the original sentence is represented as the sequence of token IDs.
Real-World Tokenization
To analyze the tokens and token IDs for your example sentence using OpenAI's tokenizer, you can follow these steps:
1. Visit the Tokenizer Tool: Go to OpenAI's Tokenizer to access the tool.
2. Input Your Sentence: Enter your example sentence in the text box.
View Tokens and IDs: The tool will display the tokens and their corresponding token IDs. Each word or subword will be split into tokens as per the GPT tokenizer's rules, and you can see how the sentence breaks down.
Token IDs

Suggested Reads- What is a Large Language Model (LLM)
Conclusion
Tokenization is the crucial first step in transforming raw text into a format that machine learning models can understand. By breaking down sentences into tokens and converting them to numerical IDs, we prepare text data for further processing and analysis. Understanding how tokenization works is essential for anyone working with NLP tasks and models.