What is a Large Language Model (LLM)? A Beginner's Guide


A Large Language Model (LLM) is an AI model designed to understand and generate text among various tasks.
AI models are trained on huge text data to perform various NLP (natural language processing) tasks. It's like an autocomplete feature but much more advanced. It learns patterns from a large amount of text data and can generate text that follows those patterns. Think of it as a text generator that writes words based on what it has learned.
Some LLMs can be experts in specific tasks and some models could be trained to do multiple tasks. It is dependent on how the model is trained. Some famous LLMs are Claude, GPT4, Mistral, Gemini, Llama etc.
What are LLMs used for?
Large Language Models (LLMs) have diverse applications:
1. Text Creation: LLMs generate content for various purposes. For instance, a marketing team might use one to draft product descriptions or blog posts.
2. Language Conversion: These models translate between languages. An international news agency could use LLMs to quickly translate articles for global audiences.
3. Text Condensation: LLMs can generate concise summaries of lengthy documents. Law firms could use this to distill complex legal texts into key points.
4. Emotional Analysis: These tools assess sentiment in written content. A movie studio could use this to gauge audience reactions to a film trailer on social media.
5. Information Retrieval: LLMs can extract relevant answers from large datasets. Libraries might use this technology to help patrons find specific information in vast archives.
6. Content Sorting: These models categorize text into predefined groups. A scientific journal could use LLMs to sort submitted papers by research field.
Why are LLMs important?
Language technology has made impressive advances recently, offering new ways to handle and create text. These developments are significant for several key reasons:
1. Boosting Productivity: Modern language tools can tackle complex tasks efficiently, allowing professionals to focus on creative and strategic work. For instance, legal researchers might use these tools to quickly sift through case law, freeing up time for in-depth analysis.
2. Bridging Communication Gaps: Enhanced translation and summarization features make information more accessible across languages. This is crucial in fields like international diplomacy, where nuanced communication is vital. Diplomats could use these tools to ensure accurate interpretation of important documents.
3. Driving Innovation: These technological capabilities are spurring the creation of novel applications across various sectors. In healthcare, we're seeing the development of intelligent systems that can analyze patient records and assist in diagnosis, potentially improving patient care.
4. Advancing Research: These tools serve as a foundation for further studies in linguistics and cognitive science. Researchers use them to explore theories about language processing and acquisition. This ongoing research not only refines the tools but also deepens our understanding of human communication.
As this field evolves, we can expect to see more applications emerge, potentially transforming how we interact with information and technology in our daily lives. From education to business analytics, the impact of these advancements is likely to be far-reaching and transformative.
Using LLMs - Inferencing
What is LLM Inferencing in Machine Learning?
Inference in machine learning refers to the process of using a trained model to make predictions or decisions on new, unseen data. It's the application phase of a machine learning model, where the knowledge gained during training is put to practical use.
How does it work?
Inference involves 3 stages, as listed below :
1. Input: New data is fed into the trained model.
2. Processing: The model applies the patterns and relationships it learned during training to this new data.
3. Output: The model produces a prediction or decision based on its processing of the input.
For an LLM like GPT, inference involves taking a prompt (input text) and generating a continuation or response based on the patterns it learned from its training data.
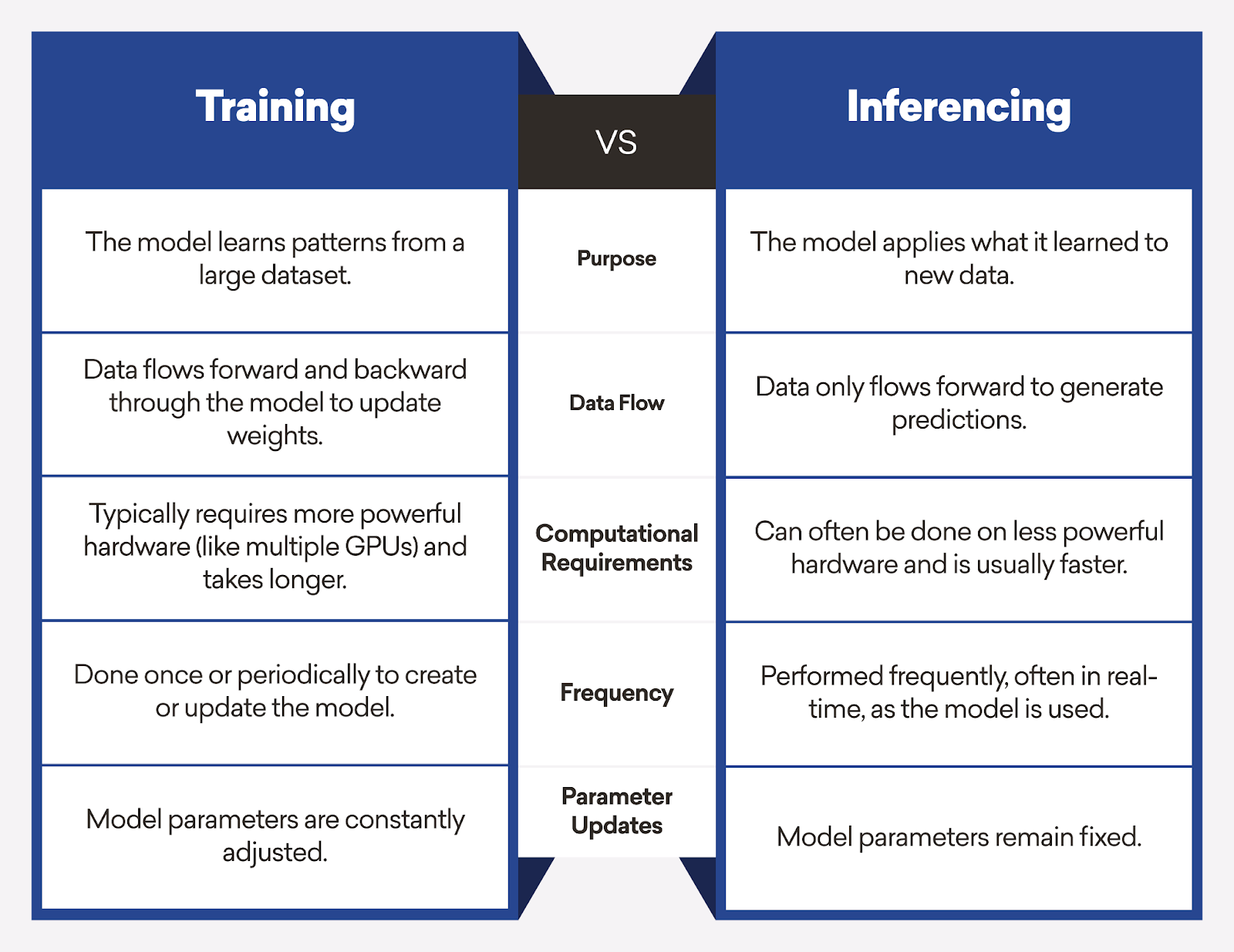
How is it different from training?
Training and inference are distinct phases in the machine learning lifecycle:
1. Purpose:
- Training: The model learns patterns from a large dataset.
- Inference: The model applies what it learned to new data.
2. Data flow:
- Training: Data flows forward and backwards through the model to update weights.
- Inference: Data only flows forward to generate predictions.
3. Computational requirements:
- Training: Typically requires more powerful hardware (like multiple GPUs) and takes longer.
- Inference: This can often be done on less powerful hardware and is usually faster.
4. Frequency:
- Training: Done once or periodically to create or update the model.
- Inference: Performed frequently, often in real-time, as the model is used.
5. Parameter updates:
- Training: Model parameters are constantly adjusted.
- Inference: Model parameters remain fixed.
Certainly. Here's a revised example section using a simpler scenario to illustrate the difference between training and inferencing:
Example: Spam Email Detection
Let's consider a machine learning model designed to classify emails as either spam or not spam (ham).
Training:
During the training phase, the model is given thousands of pre-labeled emails. For example:
1. Email: "Congratulations! You've won $1,000,000!" Label: Spam
2. Email: "Meeting rescheduled to 3 PM tomorrow" Label: Not Spam
3. Email: "Click here for a free iPhone" Label: Spam
4. Email: "Your flight ticket confirmation" Label: Not Spam
The model learns patterns associated with spam and non-spam emails based on features like word frequency, sender information, and subject lines.
Inference:
Once trained, the model can be used to classify new, unseen emails.
For example:
Input: "Limited time offer: 90% off luxury watches!"
Output: Spam (with 95% confidence)
Inference is what allows us to practically apply machine learning models, turning the complex patterns learned during training into useful outputs for real-world applications. For LLMs, this enables a wide range of applications from chatbots and content generation to language translation and text summarization. Explore our AI POCs to see how we've implemented these capabilities in real business scenarios.
Advantages of LLMs (Large Language Models)
Language processing systems have made significant strides in recent years, offering several key benefits:
1. Precision: Modern language systems demonstrate remarkable accuracy across various tasks. This precision is crucial in fields requiring exacting standards. For instance, in healthcare, these tools can assist in analyzing medical records and research papers, providing valuable insights to support clinical decisions.
2. Adaptability: These systems excel at handling diverse tasks without needing specialized training for each one. This flexibility makes them valuable across different sectors. A single system might power customer support software, generate content, and analyze public opinion, reducing the need for multiple specialized tools.
3. Expandability: These tools can process vast amounts of text, making them ideal for large-scale data analysis. This capability is essential for managing the immense volume of information generated daily. For example, market researchers can use these systems to analyze countless online reviews and social media posts, identifying consumer trends quickly.
4. Nuanced Comprehension: Current systems show an improved ability to grasp the context and produce relevant responses. This enhanced understanding leads to more natural and effective interactions. In educational technology, for instance, these systems can engage in meaningful dialogues with students, adapting to their learning pace and style.
As this technology continues to evolve, we can expect to see its impact grow across various industries, potentially transforming how we interact with information and digital systems in our daily lives.
Limitations of Large Language Models
1. Training and running LLMs require significant computational power and memory. This requirement can be a barrier for smaller organisations with limited resources.
Training a state-of-the-art LLM like GPT-4 requires access to powerful GPUs, substantial memory and vast amounts of high-quality training data which can be prohibitively expensive for some startups.
2. As an extension of the above, Developing and deploying LLMs can be expensive (due to computation and training data set requirements), limiting access to well-funded organisations. Reducing the cost of LLMs is essential to democratize their benefits.
The high cost of developing and maintaining LLMs may prevent small businesses from adopting these technologies, creating a digital divide between large and small enterprises.
3. LLMs can inherit biases present in the training data, leading to biased outputs. Addressing these biases is crucial to ensure fair and ethical use of LLMs.
Example : If an LLM is trained on text data containing gender stereotypes, it may generate biased content that reinforces those stereotypes, necessitating careful data curation and bias mitigation strategies.
4. LLMs are probabilistic. So the same query could give different answers at different times.
5. It can be challenging to understand how LLMs arrive at their conclusions due to their complex architectures. This lack of interpretability can hinder trust and adoption in critical applications.
In healthcare, doctors may be reluctant to rely on LLM-generated diagnostic suggestions if they cannot understand the reasoning behind them, highlighting the need for transparent and interpretable models.
Conclusion
Large Language Models (LLMs) have revolutionized the field of artificial intelligence by enabling more natural and nuanced interactions with machines. They are widely used for various tasks, including natural language processing, translation, content generation, and more, due to their ability to understand and generate human-like text.
The importance of LLMs lies in their versatility and capacity to handle complex language tasks, making them invaluable tools in both academic research and industry applications. However, while LLMs offer significant advantages such as high accuracy and adaptability, they also come with limitations, including high computational resource requirements and potential biases in their training data.
As the field continues to evolve, leveraging open-source LLMs provides an accessible way for developers and researchers to innovate and refine these powerful models. For those interested in exploring this further, our upcoming blog on "How To Use Open Source LLMs" will provide valuable insights and practical guidance
Frequently Asked Questions
1. What is the difference between LLM and AI?
AI (Artificial Intelligence) is a broad field focused on creating systems that perform tasks requiring human intelligence, such as learning and problem-solving. LLMs (Large Language Models) are a specific subset of AI within natural language processing, designed to understand and generate human-like text based on extensive training data.
2. What is the difference between NLP and LLM?
NLP (Natural Language Processing) is a field of AI focused on the interaction between computers and human language, encompassing tasks like translation and sentiment analysis. LLMs (Large Language Models) are advanced models within NLP, trained on vast datasets to generate and understand human-like text, exemplifying sophisticated NLP capabilities.
3. How are LLMs used in search?
LLMs are used in search engines to improve query understanding, generate more relevant search results, and provide richer, context-aware answers. They analyze and interpret user queries more accurately, offering enhanced semantic search capabilities and enabling more natural, conversational interactions with the search system.