An Implementation Guide for RAG using LlamaIndex


In Artificial intelligence (AI), the capacity to generate human-like textual content has come to be a cornerstone of innovation. One method that has won widespread interest in current years is Retrieval-Augmented Generation (RAG).
RAG combines the strengths of AI paradigms such as retrieval and generation, to create a powerful tool for text generation. In this blog post, we're going to delve into the sector of RAG and explore how it is able to practically implement the use of LlamaIndex, a current tool designed to simplify the technique.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is a kind of natural language processing (NLP) approach that leverages the strengths of each retrieval and generation model to produce extremely good textual content. Traditional technology models depend solely on patterns found out from massive datasets to generate text, which can lead to inaccuracies and a lack of context.
In contrast, RAG combines a retrieval model, which searches for relevant information in a database or knowledge graph, with a generation model, which makes use of this retrieved data to generate textual content.
This hybrid technique allows RAG to supply greater accurate, informative, and contextually relevant text, making it a suitable solution for diverse AI applications, along with chatbots, language translation, and content technology.
Introducing LlamaIndex
LlamaIndex is a powerful tool designed to simplify the process of building and fine-tuning RAG models. Developed by Meta AI, LlamaIndex is an open-source library that provides a flexible and efficient way to integrate retrieval and generation models. With LlamaIndex, developers can easily create and customize RAG models, leveraging the strengths of both paradigms to generate high-quality text.
What is LlamaIndex?
LlamaIndex is an open-source library developed by Meta AI, specifically designed to facilitate the creation and customization of RAG models. It provides a flexible and modular framework for integrating retrieval and generation models, enabling developers to build high-performance RAG systems. LlamaIndex is built on top of popular deep learning frameworks, such as PyTorch and Hugging Face Transformers, making it easy to integrate with existing workflows.
Key Features and Capabilities
LlamaIndex offers a wide range of features and capabilities that make it an ideal choice for RAG implementations:
- Modular Architecture: LlamaIndex has a modular design, allowing developers to easily swap out different components, such as retrieval models, generation models, and indexing algorithms.
- Support for Multiple Retrieval Models: LlamaIndex supports various retrieval models, including dense passage retrievers, sparse passage retrievers, and even custom retrieval models.
- Flexible Indexing: LlamaIndex provides flexible indexing capabilities, enabling developers to index large datasets and query them efficiently.
- Efficient Retrieval: LlamaIndex includes optimized retrieval algorithms, such as FAISS and HNSW, to ensure fast and efficient retrieval of relevant information.
- Support for Multiple Generation Models: LlamaIndex supports various generation models, including transformer-based models, such as BART and T5.
- Customizable: LlamaIndex provides a high degree of customizability, allowing developers to fine-tune models, adjust hyperparameters, and experiment with different architectures.
Why Use LlamaIndex for RAG Implementations?
So, why choose LlamaIndex for your RAG implementations? Here are some compelling reasons:
- Simplified RAG Development: LlamaIndex simplifies the process of building and fine-tuning RAG models, reducing the time and effort required to develop high-performance RAG systems.
- Improved Performance: LlamaIndex's optimized retrieval algorithms and modular architecture enable faster and more efficient RAG models.
- Flexibility and Customizability: LlamaIndex provides a high degree of customizability, permitting developers to test with specific architectures, models, and hyperparameters.
- Community Support: As an open-supply library, LlamaIndex has a lively network of builders and researchers who make a contribution to its boom and improvement.
- Seamless Integration: LlamaIndex integrates seamlessly with popular deep learning frameworks, making it smooth to incorporate into existing workflows.
Setting Up the Environment
The first rule of building any Python project is to create a Virtual environment.
Here is the command to create and activate a virtual environment
python -m venv venv
source venv/bin/activateOnce you are done, install the following libraries.
pip install llama-index==0.11.17
pip install llama-index-embeddings-huggingface==0.3.1
pip install llama-index-llms-groq==0.2.0
pip install python-dotenv==1.0.1
pip install einops==0.8.0
pip install gradio==5.0.2Implementing RAG with LlamaIndex
Now, import the following functions.
import gradio as gr
from llama_index.llms.groq import Groq
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import TokenTextSplitter
from llama_index.core import Settings
from llama_index.core import ChatPromptTemplate
from dotenv import load_dotenv
import osGroq and HuggingFaceEmbedding: Here, we import Groq as the language model and HuggingFace embeddings to handle the document retrieval process.
VectorStoreIndex , TokenTextSplitter, SimpleDirectoryReader: These are key components in LlamaIndex that manage the document loading, splitting, and indexing.
Settings: Used to globally set the LLM and embedding models for the entire application.
ChatPromptTemplate: Used to format the queries and responses, ensuring that the AI answers are generated according to a specific prompt structure.
dotenv: A Python package that loads environment variables from a .env file, like API keys.
Loading Environment Variables
load_dotenv()
groq_key = os.getenv("GROQ_API_KEY")In this part, the API key for Groq is loaded using the dotenv package. You should have a .env file with your credentials, for example:
GROQ_API_KEY=your-api-key-hereConfiguring the LLM and Embedding Models
llm = Groq(model="llama-3.1-70b-versatile", api_key=groq_key)
embed_model = HuggingFaceEmbedding(model_name="jinaai/jina-colbert-v2", trust_remote_code=True)Groq: We initialize Groq with a 70-billion-parameter Llama model for generative tasks. This will be used to generate responses based on the retrieved data.
HuggingFaceEmbedding: We use jinaai/jina-colbert-v2 as the embedding model. The trust_remote_code=True option is used here to trust and execute remote code from Hugging Face, ensuring you’re using the latest implementation.
Global Configuration
Settings.llm = llm
Settings.embed_model = embed_modelThis sets the LLM and embedding model globally so that they are accessible throughout the LlamaIndex pipeline.
Document Loading and Splitting
def retrieve_info(file, query):
text_splitter = TokenTextSplitter(separator=" ", chunk_size=1500, chunk_overlap=20)
documents = SimpleDirectoryReader(input_files=[file]).load_data()
nodes = text_splitter.get_nodes_from_documents(documents)TokenTextSplitter: The TokenTextSplitter breaks the documents into chunks of 1500 tokens, with a small overlap of 20 tokens between consecutive chunks. This overlap helps preserve context across splits.
SimpleDirectoryReader: Loads the documents. You would need to place your documents here for retrieval.
get_nodes_from_documents: After loading the documents, they are split into smaller nodes, which are then used for indexing.
Index Creation
index = VectorStoreIndex.from_documents(documents)The VectorStoreIndex is a core component of LlamaIndex that builds an index from the loaded and split documents. It enables fast and efficient retrieval of relevant data during the query process.
Query Retrieval
qa_prompt_str = (
"Context information from multiple sources is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the information from multiple sources and not prior knowledge, answer the query\n"
"Query: {query_str}\n"
"Answer: "
)
chat_text_qa_msgs = [
(
"system",
"You're an helpful assistant",
),
("user", qa_prompt_str),
]
text_qa_template = ChatPromptTemplate.from_messages(chat_text_qa_msgs)
index.storage_context.persist()
query_engine = index.as_query_engine(llm=llm)
query_engine.update_prompts({"response_synthesizer:summary_template": text_qa_template})
response = query_engine.query(query)
return responseThis handles the core RAG process:
- QA Prompt Structure: A qa_prompt_str is created, which defines how the retrieved context should be presented to the language model. This prompt template asks the model to answer the query without relying on prior knowledge, only using the given context.
- Chat Prompt Template: The ChatPromptTemplate customizes how the query and context are presented to the model. The system message establishes that the model should avoid referencing the context directly in its response, promoting a more natural output.
- Persisting the Index: The index is saved using index.storage_context.persist(), allowing the data to be stored and reused without reloading and re-indexing the documents.
- Query Engine: The as_query_engine() method converts the index into a query engine. The update_prompts() function updates the prompt template, and the query() method retrieves relevant data and generates a response.
Example Usage
Once you define this function, you can use it to retrieve information dynamically based on any query using gradio interface:
gr.Interface(
fn=retrieve_info,
inputs=[gr.File(type="filepath", label="Upload a file"), gr.Text(label="Enter your prompt")],
outputs=gr.Text(label="Answer to the query"),
title="RAG WITH LLAMA-INDEX",
description="Upload a document and ask queries from it to get relevant answers",
).launch(share=True)This query is processed as follows:
- The LlamaIndex retrieves relevant chunks from the indexed document.
- The language model generates a natural response based on the retrieved documents, ensuring that the answer is accurate and grounded in the context.
Example Screenshot :

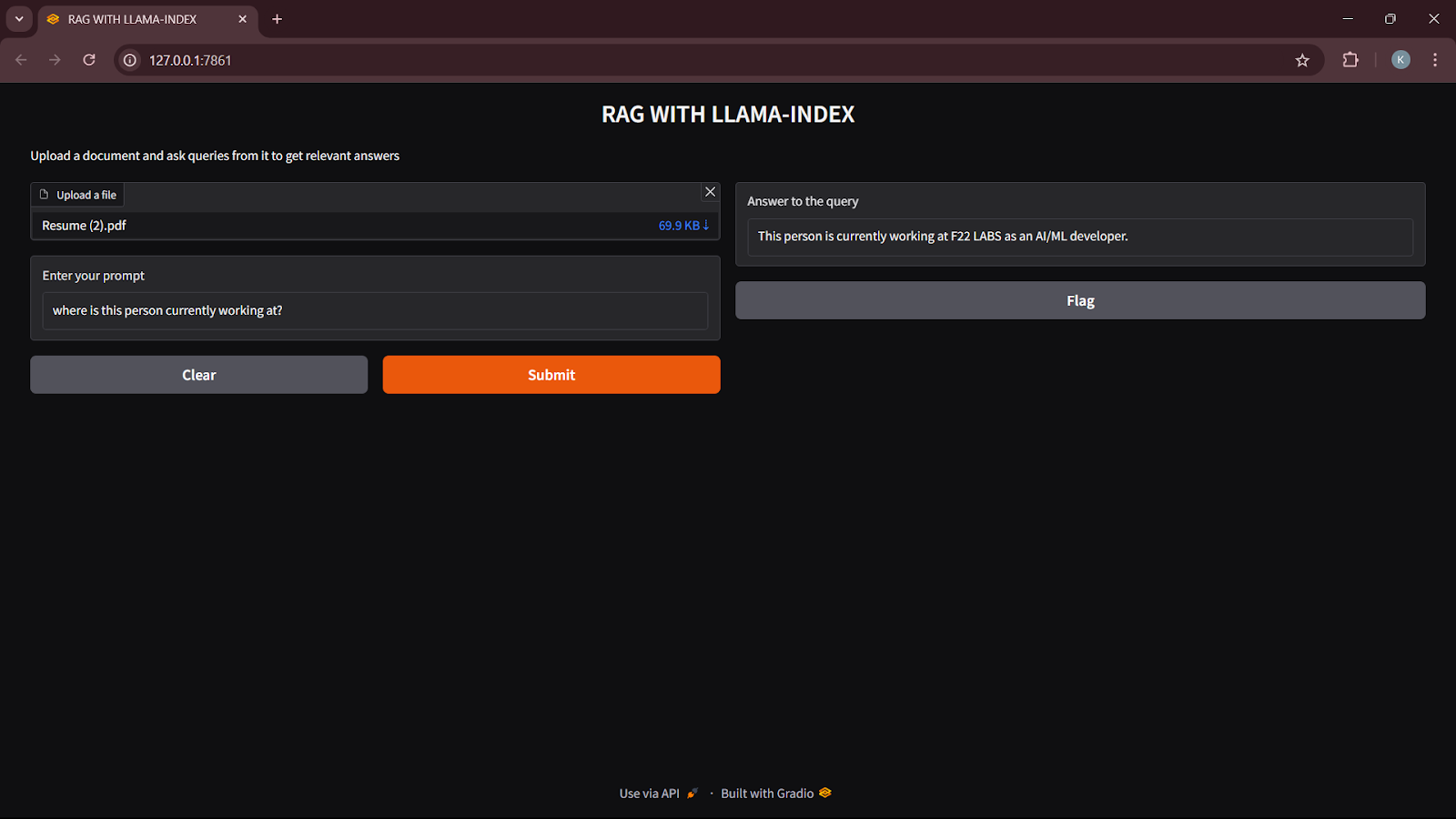
Conclusion
In this guide, we've explored the exciting world of Retrieval-Augmented Generation (RAG) and how LlamaIndex can help you unlock its potential. We've covered the key concepts, benefits, and challenges of RAG, as well as the features and capabilities of LlamaIndex.
Recap of Key Points
Here's a quick recap of the key points we've covered:
- RAG is a powerful technique: RAG combines the strengths of retrieval and generation models to produce high-quality text.
- LlamaIndex is a versatile tool: LlamaIndex is a flexible and modular framework for building RAG systems.
- RAG has many applications: RAG can be used for a wide range of tasks, from chatbots and language translation to content generation and text summarization.
- LlamaIndex is easy to use: With LlamaIndex, you can quickly and easily build and fine-tune RAG models.
- RAG has its challenges: RAG requires high-quality data, contextual understanding, and careful tuning to produce optimal results.
Frequently Asked Questions
What is Retrieval-Augmented Generation (RAG)?
RAG combines retrieval and generation models to produce accurate text by searching relevant information in a database and using it to generate contextually appropriate responses.
Why should I use LlamaIndex for RAG implementation?
LlamaIndex simplifies RAG development with optimized retrieval algorithms, modular architecture, and seamless integration with popular deep learning frameworks, reducing development time and effort.
What are the key components needed to set up RAG with LlamaIndex?
You'll need Python libraries including llama-index, huggingface embeddings, groq, python-dotenv, and gradio, plus API keys for accessing language models.