A Complete Guide to Using Whisper ASR: From Installation to Implementation


Artificial Intelligence (AI) has significantly advanced in many areas, including audio. It is transforming our interaction with and processing of sound, impacting everything from voice assistants to music production. This overview highlights the exciting developments in AI for audio, particularly focusing on Whisper, a cutting-edge Automatic Speech Recognition (ASR) model created by OpenAI.
AI in the Audio domain
Artificial intelligence (AI) has advanced greatly in many areas, including audio. It is changing how we interact with sound, influencing things like voice assistants and music. AI helps us analyze, create, and modify sound with improvements in speech recognition, music composition, and noise reduction. These innovations are reshaping industries such as entertainment, telecommunications, and accessibility. Some key areas where AI is making a significant impact include:
- Speech recognition and synthesis
- Music generation and analysis
- Sound design and audio effects
- Noise reduction and audio enhancement
- Audio event detection and classification
These advancements are transforming industries such as entertainment, telecommunications, and accessibility services, making audio technology more powerful and user-friendly than ever before.
Automatic Speech Recognition
Automatic Speech Recognition (ASR) is a key aspect of AI in the audio field. It involves machines detecting and categorizing different sounds, such as speech, music, and ambient noise. ASR systems employ machine learning algorithms to process audio signals and derive useful information from them. Some common applications of ASR include:
- Speech-to-text conversion
- Voice command systems
- Audio content analysis for media platforms
- Security and surveillance (e.g., detecting unusual sounds)
What is the Whisper ASR?
Whisper is a cutting-edge Automatic Speech Recognition (ASR) model created by OpenAI and introduced in September 2022. It marks a major advancement in speech recognition technology, distinguished by its ability to handle multilingual speech recognition, translation, and language identification with high accuracy. Key features of Whisper ASR include:
- Training on a varied dataset of 680,000 hours of multilingual and multitask data.
- Capability to transcribe speech in various languages and translate it into English.
- Strong performance across different accents and background noises.
- Open-source availability, enables researchers and developers to utilize and enhance the model.
Benefits of Whisper ASR
Whisper's capabilities extend far beyond simple speech-to-text conversion. See our AI POC implementation where we've used Whisper for real-time voice-to-voice conversation and automated form filling. Here are some additional ways Whisper is helping to advance the field of audio AI:
Multilingual Communication
Whisper's standout feature is its multilingual capability, allowing it to recognize, transcribe, and translate speech in multiple languages into English. This ability facilitates:
- Real-time translation for international business meetings
- Automatic subtitling for foreign films and videos
- Transcription and translation of podcasts for global audiences
- Language preservation for less commonly spoken languages
Enhancing Voice Assistants with Whisper
Whisper has the potential to significantly upgrade voice assistants by enhancing their speech recognition and language understanding capabilities. It can improve:
- Handling of various accents and dialects
- Accuracy in responding to complex queries
- Understanding of context and intent
- Multilingual support without manual switching
These improvements will contribute to more accurate, versatile, and natural interactions, making voice assistants more advanced and user-friendly.
Whisper for Media Transcriptions
The media industry can greatly benefit from Whisper's capabilities, particularly in the area of transcription. Whisper can quickly and accurately transcribe audio content from various sources, including:
- Podcasts and radio shows
- News broadcasts and interviews
- Movies and TV shows
- User-generated content on social media platforms
This automatic transcription can save content creators and media companies significant time and resources, while also improving the searchability and accessibility of their content.
Whisper's Performance in Noisy Environments
Handling background noise and poor recording conditions is a common challenge in speech recognition. Whisper excels in these tough environments, making it ideal for:
- Transcribing live events or outdoor recordings
- Processing phone calls or low-quality audio
- Recognizing speech in busy or noisy places
This robustness makes Whisper a versatile tool for many different applications and industries.
Supported Models and Languages
Whisper is available in several model sizes, each offering a different balance between accuracy and computational requirements:
Tiny, Base, Small, Medium, Large-v1, Large-v2, Large-v3
The larger models generally offer better performance but require more computational resources to run. Users can choose the appropriate model size based on their specific needs and available hardware.
In terms of language support, Whisper can transcribe speech in over 99 languages, including Whisper supports numerous languages, including English, Mandarin Chinese, Spanish, Hindi, French, German, Japanese, Korean, and many others.
This extensive language support makes Whisper a truly global tool for speech recognition and translation.
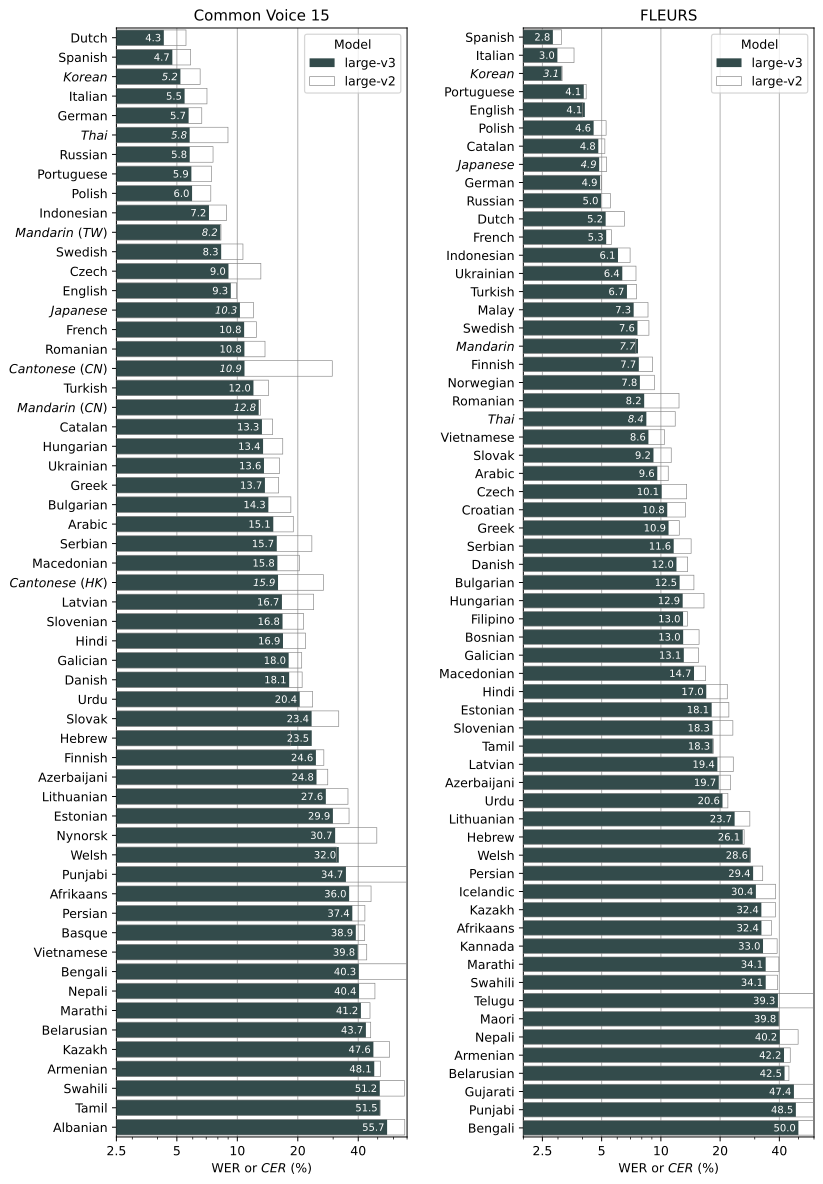
Whisper’s Supported Languages and Performance
Whisper's performance varies widely depending on its supported language. The figure below shows how the large-v3 and large-v2 models perform across different languages. It uses Word Error Rates (WER) or Character Error Rates (CER, shown in italics) from evaluations on the Common Voice 15 and Fleurs datasets.
Practical Guide To Implementation
Whisper is open-source and can be used by developers and researchers in various ways, including through a Python API, command-line interface, or by using pre-trained models. Here's a simple example of how to use Whisper in Python:
Installation
Before diving into usage, you need to install the necessary packages. You can do this using pip,
For the base Whisper library:
pip install git+https://github.com/openai/whisper.git Or,
pip install whisperQuick setup
Command-line and Python Usage
Whisper can be used directly via the command-line or embedded within a Python script. For command-line usage, transcribing speech in audio files is as simple as running:
whisper audio.flac audio.mp3 audio.wav --model mediumTo use Whisper in a Python script, you can import the package and use the load_model and transcribe functions, like so:
import whisper
model = whisper.load_model("large-v2")
result = model.transcribe("audio.mp3")
print(result["text"])Pipeline
Whisper can be seamlessly utilized through the pipeline method from the transformers library, offering a streamlined approach to automatic speech recognition. By installing the transformers package and initializing a Whisper pipeline, users can efficiently transcribe audio files into text.
This setup simplifies integrating Whisper into various applications, making advanced speech recognition more accessible and straightforward.
from transformers import pipeline
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = ["audio.mp3"]
texts = transcriber(audio_filenames)
print(texts)Faster-Whisper (optimized version of Whisper):
This code uses the faster-whisper library to transcribe audio efficiently. It initializes a Whisper model and transcribes the audio file "audio.mp3", retrieving time-stamped text segments. The output displays each segment's start and end times along with the transcribed text.
Installation
pip install faster-whisperInference
from faster_whisper import WhisperModel
model = WhisperModel("large-v2")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
Limitations and Conclusion
Whisper, while highly advanced, faces several challenges in real-time applications:
- Computational Requirements: Larger models (Medium, Large) require significant computational power, making them ideal for offline tasks. Smaller models (Tiny, Base) provide faster processing but may reduce accuracy in complex or noisy environments.
- Latency in Real-time Use: Whisper's real-time transcription can experience latency, which limits its effectiveness in time-sensitive tasks like live captioning or virtual meetings.
- Resource Constraints: Running larger models on low-end hardware can cause performance issues. Optimizations like batching and chunking audio can help, but require additional effort.
- Privacy and Data Security: Cloud-based processing raises privacy concerns, as sensitive audio data may be transmitted externally. On-device processing mitigates this but demands more hardware.
- Problems with Accents and Dialects: Depending on the accent and dialect, accuracy may vary, and particular speech patterns or geographical areas may require fine-tuning.
- Managing Long Audio Files: Real-time processing of lengthy audio files can be memory-intensive, although segmentation and streaming transcription can help lighten the strain.
- Energy Consumption: Due to their higher energy consumption, larger versions are not suitable for continuous real-time applications such as round-the-clock monitoring.
- Scalability: As expensive operations result from powerful hardware and infrastructure, large-scale deployments have problems with scalability.
Conclusion
Whisper represents a significant leap forward in AI-powered audio processing, offering multilingual speech recognition and translation capabilities. Its versatility and accuracy across various environments make it valuable for industries ranging from media to telecommunications.
While Whisper faces challenges in real-time applications and resource management, its open-source nature encourages continuous improvement and innovation. As AI in audio continues to evolve, Whisper stands as a powerful tool that's reshaping how we interact with and understand spoken language.
Its impact on global communication, accessibility, and content creation is likely to grow, driving further advancements in the field of audio AI.
FAQ's
1. What is Whisper ASR and how does it differ from other speech recognition models?
Whisper is an advanced ASR model by OpenAI that excels in multilingual speech recognition, translation, and transcription. It's trained on diverse data and performs well across various accents and noisy environments.
2. How can I implement Whisper in my projects?
Whisper can be implemented using Python or command-line interfaces. Install it via pip, then use the whisper.load_model() and transcribe() functions in Python, or run it directly from the command line.
3. What are the limitations of Whisper for real-time applications?
Whisper faces challenges in real-time use due to computational requirements, latency issues, and resource constraints. Larger models may not be suitable for continuous real-time applications or low-end hardware.